Table of Contents
- 1. Scenario: When “good enough” AI content quietly tanks your SEO
- 2. Research modes compared: single‑prompt AI, multi‑source AI research, and manual work
- 3. How to set up a multi‑source AI research stack
- 4. Consensus‑driven AI research that mirrors Google’s evaluation
- 5. Designing a hybrid AI + human editorial pipeline for E‑E‑A‑T
- 6. Step‑by‑step workflow to ship E‑E‑A‑T‑aligned AI content
- 7. Practical tips, prompts, and guardrails for technical teams
- 8. Conclusion and next steps
1. Scenario: When “good enough” AI content quietly tanks your SEO

Imagine you’re a marketing manager who has just convinced your exec team that AI content is the shortcut to hitting next quarter’s traffic targets. Your dev lead spins up a simple “write me a blog post about X” workflow using an AI content platform. Within weeks you’re publishing dozens of neat, on‑brand articles.
For a month, things look fine. Then rankings slide. Your YMYL pages start losing impressions. A few factually shaky paragraphs get flagged internally. Someone spots that a “stat” the model quoted literally does not exist. You haven’t only wasted content budget – you’ve weakened your E‑E‑A‑T signals right when AI overviews are reshaping the SERP, something specialist SEO coverage has been dissecting for years.
This article addresses that exact situation. It focuses on how technical implementers can set up multi‑source AI research, configure a hybrid AI + human pipeline, and ship E‑E‑A‑T‑aligned content at scale with platforms like Lyfe Forge. We will stay concrete: specific tools, prompting patterns, quality checks, and when to choose single‑prompt AI, multi‑source research, or full manual work so Google sees your output as “valuable, relevant, and trustworthy” even if AI helped write it. https://www.fonzy.ai/blog/ai-content-hallucinations-factual-reliability-seo
2. Research modes compared: single‑prompt AI, multi‑source AI research, and manual work
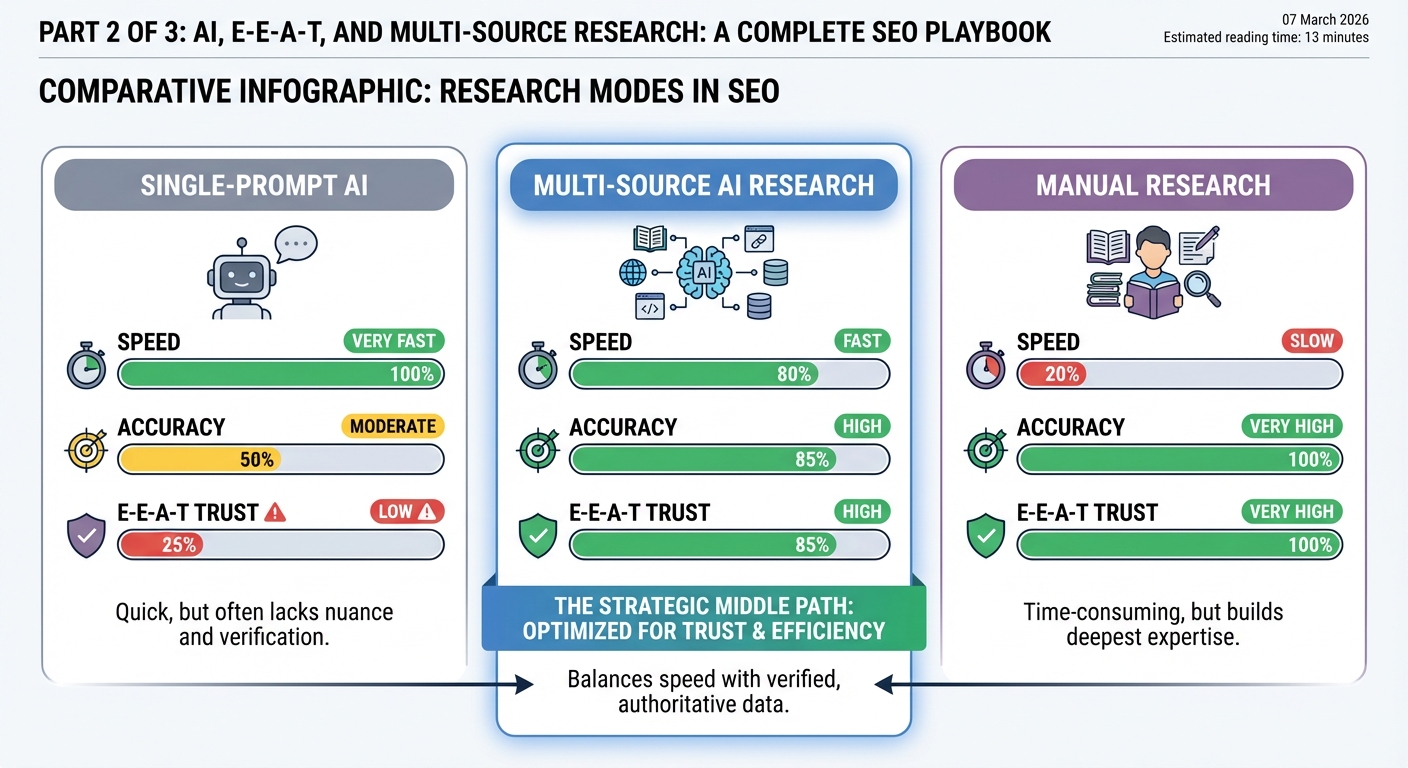
If you are designing a content workflow, you effectively choose between three research modes on every brief: single‑prompt AI, multi‑source AI research, or traditional manual digging. Each has different speed, accuracy, and E‑E‑A‑T implications.
Single‑prompt AI is the classic “Write a 1500‑word article about X” call. It is blazing fast and cheap, but it relies heavily on the model’s internal training data. That raises hallucination risk and often results in generic, citation‑free content – exactly the sort of material Google is trying to filter out as low‑quality AI noise, especially for YMYL topics where real‑world harm is on the table, as outlined in Google’s E‑E‑A‑T guidance. However, some experts argue that Google’s stance is less about outlawing AI and more about rewarding anything that’s genuinely useful. Google has been explicit that it doesn’t automatically penalize AI‑generated content; what it cares about is whether a page demonstrates real experience, expertise, and trustworthiness. In other words, a single‑prompt workflow isn’t inherently toxic to your rankings – if you layer in strong prompts, human oversight, fact‑checking, and clear authorship, you can still ship AI‑assisted content that meets E‑E‑A‑T standards. The real risk isn’t the use of AI itself, but treating “Write a 1,500‑word article about X” as a complete content strategy instead of a starting point in a more rigorous, human‑guided process.
Manual research at the other extreme is slow but very precise. A subject matter expert combs through academic papers, government sites, and top industry resources. From an E‑E‑A‑T perspective, it scores well on expertise and trust, especially when backed by citations and lived experience. The trade‑off is scale; your team simply cannot do this for fifty pages a month without serious headcount.
Multi‑source AI research sits in the middle. You use AI tools to query multiple authoritative sources, extract and synthesise results, and generate drafts grounded in verifiable citations. Compared with single‑prompt AI, you trade a little speed for a major gain in factual reliability and E‑E‑A‑T alignment, echoing best practices from recent SEO research on AI content. Compared with pure manual work, you preserve depth but drastically cut research time.
From a practical standpoint, your architecture should support all three modes. Quick non‑YMYL explainers might rely on single‑prompt AI with light checks. Core money pages and anything in health, finance, or legal domains should default to multi‑source AI plus human review. Truly sensitive or novel topics still justify full manual research by an expert who then uses AI only for structuring and polishing.
3. How to set up a multi‑source AI research stack
Multi‑source AI research is less about one magical tool and more about how you configure the stack. At minimum you want: a retrieval layer, one or more large language models, and a way to log sources and prompts for later audit, ideally inside your chosen AI content platform.
On the retrieval side, think in three buckets. First, live web search via tools like Perplexity or a custom search API to pull data from high‑authority domains: government (.gov.au), universities (.edu), and established industry publishers. Second, your own corpus – PDFs, past blog posts, whitepapers – indexed in a vector store such as Pinecone or Elasticsearch. Third, specialist datasets where relevant, like medical guidelines or financial regulations, stored separately with explicit tagging.
Your LLM layer can be a hosted model (e.g. GPT‑4 or Gemini) fronted by a service that accepts both prompt and retrieved snippets. This is effectively Retrieval‑Augmented Generation (RAG), which multiple studies suggest can cut hallucination rates by around 40% or more when configured carefully, because the model is grounded in supplied, verifiable context rather than free‑wheeling on its training data, a pattern very much in line with modern E‑E‑A‑T‑driven optimisation.. https://www.fonzy.ai/blog/ai-content-hallucinations-factual-reliability-seo
For technical teams at a marketing‑tech startup like Lyfe Forge, a sensible pattern is: a backend microservice that orchestrates retrieval (multiple search calls, plus vector store lookup), then calls the LLM with a structured prompt template. Every request stores: input prompt, retrieved URLs, model response, and a minimal quality score (for example, presence of citations). This history becomes gold later when you refine prompts or investigate why a specific article under‑performed.
Finally, do not skip observability. Wire simple logging and, if you have capacity, a small internal dashboard that tracks which sources are most often used, which prompts correlate with editor rewrites, and where hallucinations slipped through. That gives you concrete levers to tighten the workflow rather than guessing, and pairs neatly with reviewing your own content index and sitemap data.
4. Consensus‑driven AI research that mirrors Google’s evaluation
Google’s systems do not trust a single page; they cross‑reference many documents to detect consensus, especially on YMYL topics. Your research workflow can echo this behaviour by design, increasing the odds that what you publish lines up with what algorithms expect to see, as discussed in specialist E‑E‑A‑T analysis.
The key is to treat each claim in your draft as something that must be supported by multiple, independent sources. Multi‑source AI research helps here: the retrieval layer queries several authoritative domains and surfaces snippets that agree (or conflict). The LLM then synthesises these, but crucially, you keep the original citations attached so a human editor can see where everything came from.
A practical pattern is to have the AI first output a structured “research brief” instead of prose. For each subheading, ask for: a short summary, 3‑5 supporting URLs, any disagreements between sources, and a confidence level. Only in a second step do you request a narrative draft, instructing the model to stick to the consensus view and flag edge cases as such.
This process reduces hallucinations because the model is constrained to information already vetted through retrieval and cross‑checking. It also aligns neatly with E‑E‑A‑T expectations: expertise reflected in accurate facts, authoritativeness expressed through references to respected publishers, and trustworthiness supported by transparent sourcing. Over time, as you consistently publish such well‑grounded pieces across a topic cluster, you accumulate topical authority that helps rankings and AI‑powered overviews surface your brand. https://seranking.com/blog/google-eat-ymyl/?utm_source=openai
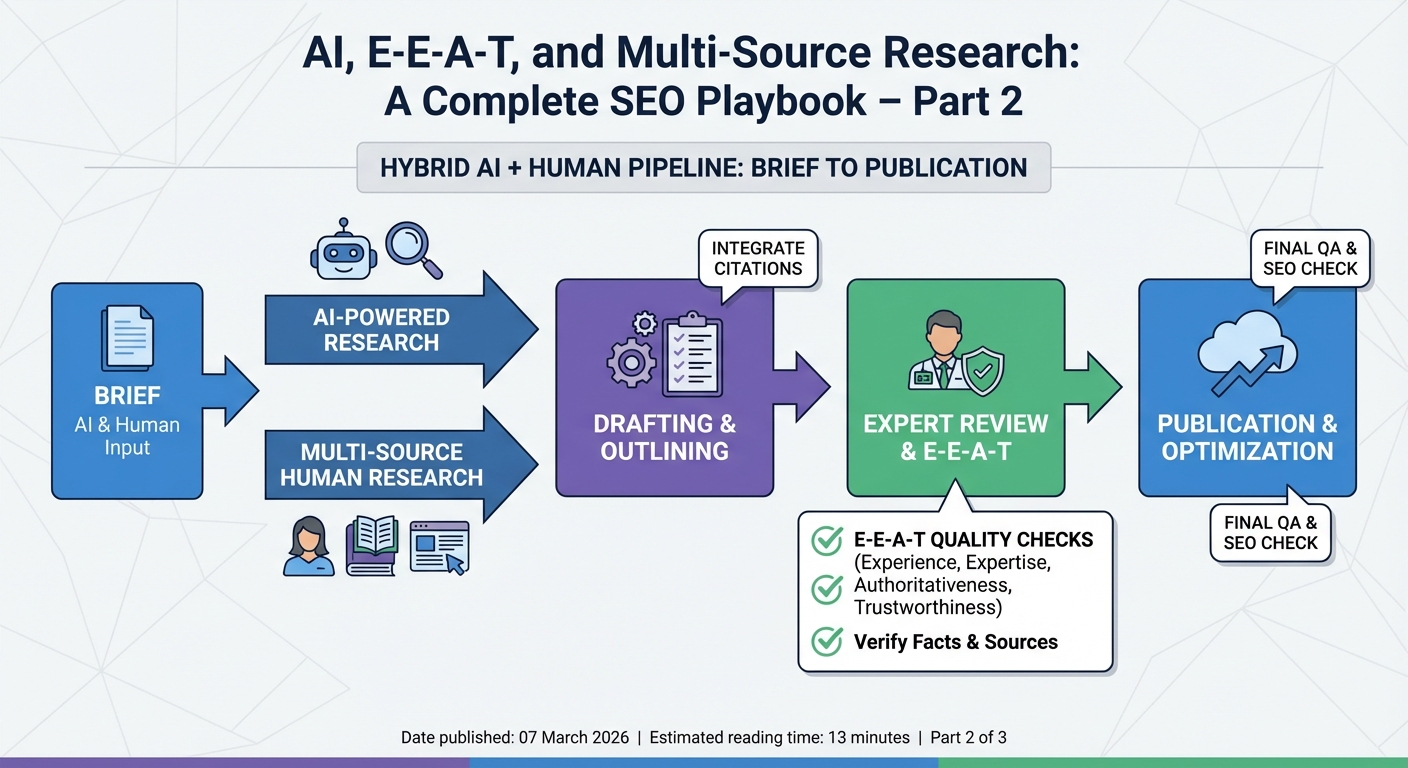
5. Designing a hybrid AI + human editorial pipeline for E‑E‑A‑T
Even the best multi‑source stack still needs human judgment. The strongest results come from a hybrid pipeline where AI handles research and drafting at scale, while subject matter experts and editors guard nuance, context, and risk.
Think of the pipeline as a series of “gates” rather than a single pass. Gate one: AI research and outline. Gate two: human approval of that outline – checking that headings match search intent and that the brief references adequate sources, especially for YMYL material. Gate three: AI draft generation, grounded in the approved brief. Gate four: expert review for factual depth, alignment with current standards, and injection of first‑hand experience.
That “experience layer” is where your human team earns its keep. Google’s own guidelines point out that first‑hand use, case studies, and real outcomes are crucial signals, and those cannot come from a model. Your editors should be adding anecdotes, client results, photos, or quotes that demonstrate real‑world engagement with the topic, while staying consistent with your Terms of Service and Privacy Policy. https://jumpfly.com/blog/the-history-of-truth-googles-e-e-a-t-ymyl/?utm_source=openai
A final gate focuses on trust mechanics: is there a clear byline with credentials, is the content date‑stamped and, where necessary, medically or legally reviewed? For AI‑assisted pieces, many Australian organisations are now considering transparent labelling, in line with emerging local guidance around synthetic content disclosure, to further support user trust.
From a technical standpoint, you can capture this pipeline in a simple ticketing flow (Jira, Linear, Notion) with required fields at each stage: research URLs, draft link, reviewer notes, and final publication URL. Over time this becomes a dataset you can mine to refine prompts and decide where to invest more human time.
6. Step‑by‑step workflow to ship E‑E‑A‑T‑aligned AI content
Let’s stitch the pieces together into a concrete, repeatable workflow you can hand to an engineering‑minded content team. The aim is to keep speed, but not at the cost of E‑E‑A‑T.
Step 1 – Brief and query design. Marketing defines topic, target queries, page type (informational, commercial, or mixed), and risk level (YMYL or not). Your service turns this into a structured JSON brief that the AI research microservice consumes, including a list of preferred domains (for example, government, universities, leading industry publications) and any internal rules drawn from your platform terms.
Step 2 – Multi‑source research aggregation. The research service fires several parallel calls: web search against whitelisted domains, vector search over your internal corpus, and, if you have them, API calls to specialist datasets. Results are cleaned and normalised into a store of snippets tagged with URL, domain authority, and retrieval timestamp.
Step 3 – AI‑generated research summary. You pass the brief plus the snippets into the LLM with a prompt such as, “Summarise consensus views, list key facts with citations, and highlight disagreements.” The output is a research dossier, not yet a blog post.
Step 4 – Human review of the dossier. An editor checks that the sources are credible and that the topic coverage feels complete. For YMYL content, they might add extra mandatory sources such as government regulators or peer‑reviewed papers. Only then do they tick “ready for draft.”
Step 5 – AI drafting with experience placeholders. A second prompt asks the LLM to craft the full article, but with explicit placeholders like “[INSERT CLIENT CASE STUDY ABOUT X]” or “[EDITOR: ADD QUOTE FROM DIETITIAN]”. This keeps structure and SEO friendly headings while clearly flagging where human experience must be inserted.
Step 6 – Expert pass and E‑E‑A‑T audit. Subject experts fill the placeholders, adjust nuanced claims, and cross‑check key facts. A simple checklist works well here: citations present, first‑hand or case‑based examples added, author byline accurate, intent clearly helpful and non‑harmful, and disclosures that align with your accessibility commitments. https://jumpfly.com/blog/the-history-of-truth-googles-e-e-a-t-ymyl/?utm_source=openai
Step 7 – Publication and telemetry. Once published, basic metrics (organic impressions, CTR, time on page, scroll depth, conversions) feed back into your content database. After a few months you can correlate workflow choices (how many sources, which prompts, how much human editing) with performance, then refine the process based on real outcomes rather than gut feel, and compare against other AI content tooling investments.
7. Practical tips, prompts, and guardrails for technical teams
To wrap up, here are concrete tactics you can wire into your stack so multi‑source AI research consistently supports E‑E‑A‑T rather than quietly undermining it.
1. Hard‑code domain policies. Maintain an allow‑list and deny‑list for retrieval. For YMYL topics, force a minimum quota of government, academic, and top‑tier industry sites. This single configuration change dramatically narrows the space where hallucinations can hide, and dovetails with modern E‑E‑A‑T optimisation strategies.
2. Use two‑stage prompting. Always separate “research and consensus building” from “narrative drafting.” For example, first prompt: “From these sources, extract key facts, disagreements, and citations.” Second prompt: “Using only those facts, write a structured article…” This reduces the chance that the model freelances.
3. Log citations as first‑class data. Do not treat links as decoration. Store them alongside each section in your CMS, so editors and even readers can quickly trace back important claims. That transparency is central to trust in an AI era where users are rightly sceptical of generic content, and it should sit comfortably with your API and data‑use policies.
4. Tune for different content types. Not every page deserves the same rigour. Build simple presets: “high‑risk YMYL,” “standard informational,” “low‑risk lifestyle.” Each preset can adjust the number of required sources, the depth of the research summary, and how much expert review time is budgeted.
5. Embrace honest limits of AI. Make it normal for your prompts to say “If you are unsure, say so.” Encourage the model to suggest where a human expert should weigh in. E‑E‑A‑T is not about pretending AI is a doctor, lawyer, or financial planner; it is about using AI to surface the best current knowledge so real experts can make judgement calls, a nuance underlined in recent commentary on AI‑generated SEO content. https://seranking.com/blog/google-eat-ymyl/?utm_source=openai
Done well, this hybrid, multi‑source setup lets your team publish more, faster, without falling into the trap of low‑quality AI spam that erodes rankings and trust. Instead, you gradually establish your brand as one of the rare voices that pairs technical scale with genuine expertise and clear human accountability, particularly when anchored in a robust AI content creation platform.
8. Conclusion and next steps
AI is not going away, and Google is not giving you a pass because “the model wrote it.” The sites that win in the next wave of search will be the ones that treat AI as a research and drafting engine, not an oracle, and that surround it with strong multi‑source retrieval, consensus checks, and real human expertise, just as E‑E‑A‑T‑focused SEO playbooks recommend.
As a technical implementer, your role is pivotal. The way you set up prompts, retrieval rules, logging, and review stages directly shapes whether your content feeds the flood of generic AI articles or stands out as reliable, experience‑rich material that meets E‑E‑A‑T expectations.
Your practical next step is to pick one high‑value topic cluster, configure a slim version of the workflow described here, and run it end‑to‑end for a month. Measure what happens, tweak, repeat. When you are ready to move from experiments to a full multi‑source AI content engine, Part 3 of this series will zoom in on how smaller and local brands can translate these mechanics into concrete trust‑building and authority in their own niches, leveraging purpose‑built platforms like Lyfe Forge’s AI content suite.
Frequently Asked Questions
What is multi‑source AI research in SEO and why does it matter for E‑E‑A‑T?
Multi‑source AI research means configuring your AI workflows to pull from multiple, high‑quality data sources (first‑party data, trusted third‑party sites, SMEs, internal docs) instead of letting the model free‑write from its training data alone. This matters for E‑E‑A‑T because it improves factual accuracy, allows you to show your sources, and makes it easier to demonstrate real expertise and experience rather than generic AI‑generated fluff.
Can using AI to write SEO content hurt my E‑E‑A‑T and rankings?
AI content can hurt E‑E‑A‑T if it’s published as a high‑volume, lightly edited firehose full of generic claims, weak sourcing, and uncorrected errors. But when AI is used as a drafting assistant inside a strong editorial framework—with clear authorship, fact‑checking, transparent citations, and an active correction process—Google is far more likely to see it as supporting, not undermining, your authority.
How do I set up an AI + human content workflow that is safe for YMYL topics?
For YMYL pages, start with human subject‑matter experts defining the outline, thesis, and key claims, then use AI to draft sections based on approved source material. Require manual review for every claim and stat, add citations to authoritative sources, run a dedicated fact‑checking pass, and ensure a named expert author or reviewer signs off before anything goes live.
When should I use a simple single‑prompt AI blog workflow vs multi‑source research?
Single‑prompt AI (“write a blog about X”) is only appropriate for low‑stakes, non‑YMYL, and non‑core pages where nuance and accuracy are less critical, and even then it needs human review. Use multi‑source research for any content that could influence money, health, legal, financial, or high‑impact decisions, or where your brand’s authority and differentiation really matter.
How can I stop AI content hallucinations from damaging my SEO?
Constrain the model to verified sources (RAG, curated knowledge bases, internal documentation) and explicitly instruct it not to invent stats, quotes, or sources. Add mandatory QA stages: automated link checking, manual spot‑checks on every stat and claim, and a clear process for quickly correcting or pruning pages when errors are found.
What are signs that my current AI content strategy is quietly hurting SEO performance?
Warning signs include slow but consistent ranking drops on YMYL pages, declining impressions for previously stable queries, and internal teams flagging factual issues or unsourced stats. If your new AI‑assisted content isn’t earning links, isn’t cited by others, or has low engagement compared to older human‑written pieces, your E‑E‑A‑T signals may be weakening.
How does Lyfe Forge help teams build E‑E‑A‑T‑aligned AI content workflows?
Lyfe Forge focuses on technical implementation: configuring multi‑source AI research, building hybrid AI + human pipelines, and setting up quality checks for fact accuracy and sourcing. They help you decide when to use AI drafts, when to go full manual, and how to embed authorship, citations, and review steps so your content consistently meets E‑E‑A‑T expectations at scale.
What’s the difference between AI overviews in Google and my own AI‑generated content?
Google’s AI overviews synthesize information from across the web using its own ranking and quality systems, while your AI content is only as good as your prompts, sources, and editorial process. If your articles are thin, generic, or error‑prone, they’re less likely to be cited or reflected positively in those overviews, which can reduce your brand’s visibility even if you keep publishing more content.
How do I decide which sources to include in a multi‑source AI research setup?
Prioritize your own first‑party data (product docs, case studies, internal research) and a vetted list of external authoritative sites relevant to your niche. Explicitly exclude low‑quality domains, UGC with weak moderation, and outdated resources, and update your source list regularly so the AI is always drawing from current, trustworthy material.
Do I need to show citations and authors if AI helped write the article?
Yes, you should still show a real human author or reviewer and list key sources, even if AI produced the first draft. Clear bylines, reviewer credits, and accessible references signal accountability and traceability, which directly support E‑E‑A‑T and help mitigate concerns about AI involvement.